
获取内容网址
有常规模式和高级模式两种。
1.常规模式:
- 该模式默认抓取一级地址,即从起始页源代码中获取到内容页A链接。
- 它有2种方式:a.自动获取地址链接 b.手动设置规则获取。
2.高级模式:
- 该模式对0级,多级,POST类型网址的抓取有效。
- 即起始网址就是内容页网址;
- 或者需要对多级列表网址采集才能得到最终内容页链接;
- 或者是post网址类型抓取等情况下使用高级模式。
下面对常规模式采集进行具体说明。高级模式 详细教程后续分解
[常规模式]a.自动获取地址链接
自动获取地址链接:自动获取该级列表页中所有的a标签
<a href="URL">内的URL链接
如新浪内地新闻:http://roll.news.sina.com.cn/news/gnxw/gdxw1/index.shtml获取结果如图:
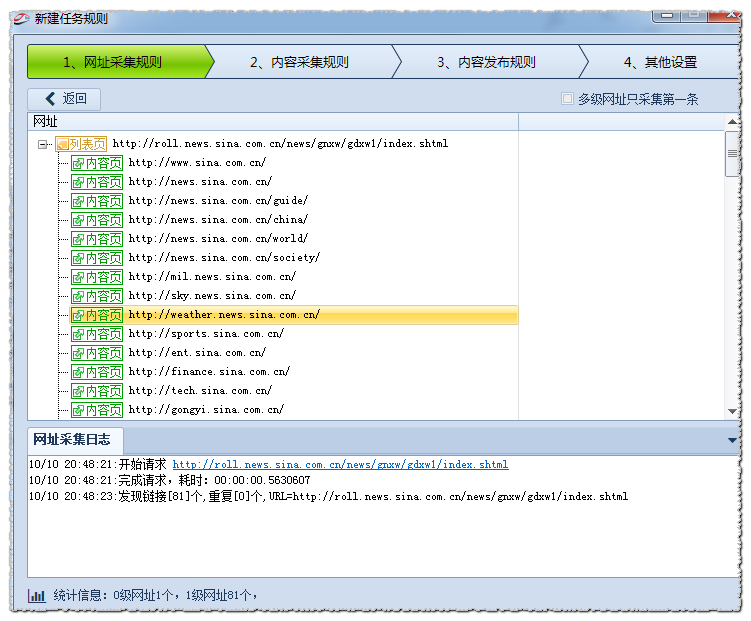
共81个一级网址,但实际我们需要抓取的1级网址是每页40个,
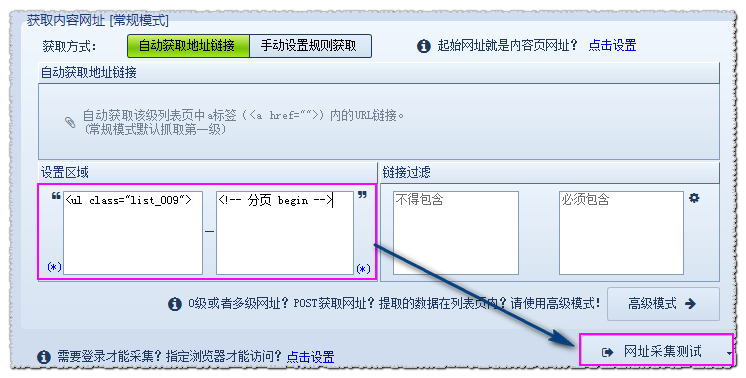
所以我们可以通过区域设置和链接过滤设置 来获取我们所需要的链接。用谷歌浏览器在网页上右击——查看网页源代码,分析源码得出:
开始字符串为<ul class=”list_009″>
结尾字符串为 <!– 分页 begin –>
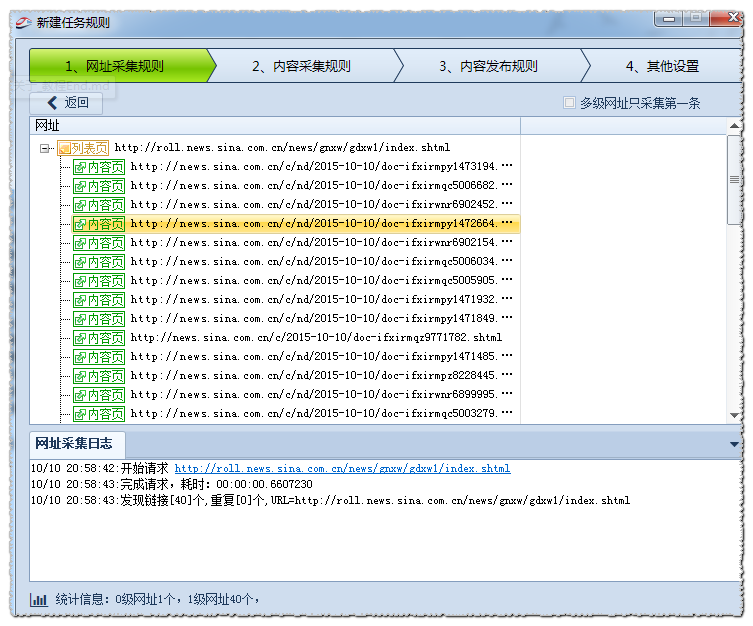
这样我们再点击网址采集测试,可以看出结果是正确的。
[常规模式]b.手动设置规则获取
对于有些由脚本生成的网址,采集器不能自动识别,此时就要手动设置规则获取了。
手动设置规则获取设置原理是编写脚本规则,去和源代码里的内容匹配,获取到自己设置的参数即可。
其中提取规则里的[参数],(*) ,[标签:XXX] 都是通配符,可以统配任意字符,
区别在于[参数]有返回值,一般用于拼接地址,(*)没有返回值,[标签:XXX]有返回值,返回值给标签。如新浪内地新闻:http://roll.news.sina.com.cn/news/gnxw/gdxw1/index.shtml
有如下源码:
<li><a href="http://news.sina.com.cn/c/nd/2015-10-10/doc-ifxirmpy1472664.shtml" target="_blank">山西公布政府部门责任清单 建立拒腐机制</a><span>(10月10日 20:20)</span></li>
<li><a href="http://news.sina.com.cn/c/nd/2015-10-10/doc-ifxirwnr6902154.shtml" target="_blank">河南登封市长被举报建寺涉贪 与释延鲁关系密切</a><span>(10月10日 20:14)</span></li>
<li><a href="http://news.sina.com.cn/c/nd/2015-10-10/doc-ifxirmqc5006034.shtml" target="_blank">张家界国土局副局长涉严重违纪被查</a><span>(10月10日 19:45)</span></li>此时,我们可以取其中的一条代码作为循环匹配,把我们要获取的链接替换成[参数],需要采集到的值替换成标签。 如:
<li><a href="[参数]" target="_blank">[标签:title]</a><span>([标签:time])</span></li>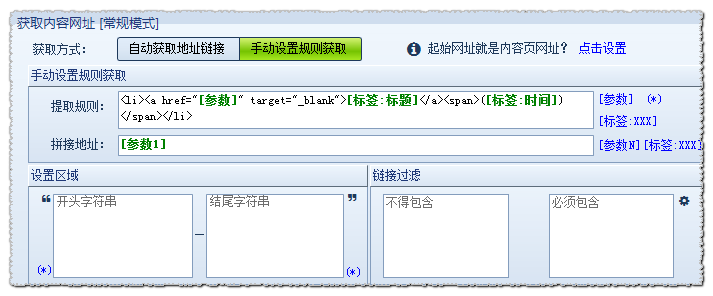
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。