
对从内容页面提取的数据进行进一步处理,可以同时添加多个操作,按照从上到下的顺序来执行。
也就是说,上个步骤的结果会作为下个步骤的参数。
- 提取内容为空:如果提取内容为空,则使用正则匹配从原始页面中再次提取
- 内容替换/排除:将采集到的内容进行字符串替换,如需排除,则替换为空字符串即可
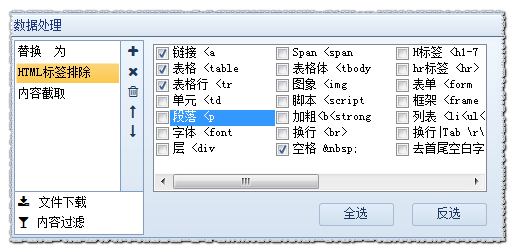
- html标签过滤:过滤指定html标签,比如<a ,<font
- 字符截取:通过开始和结束字符串对内容进行截取
- 纯正则替换:通过强大的正则表达式进行复杂的替换。
- 数据转换:包括将结果简转繁、将结果繁转简、自动转化为拼音和时间修正转化
- 智能提取:包括提取第一张图片、智能提取时间、智能提取邮箱、智能提取手机号码、智能提取电话号码
- 高级功能:包括自动摘要、自动分词、Http请求、字符编码转换、同义词替换、空内容缺省值、内容加前后缀、随机插入、运行C#代码、批量内容替换,统计标签字符串长度等一系列功能。
- 补全单网址:将当前内容作为一个网址进行补全。
- 文件下载:可以自动探测并下载文件,可设置下载路径和文件名样式。
- 内容过滤:对于一些不符合条件的记录,可以通过设置内容过滤来删除或标记为未采。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。